大语言模型虽然具有较强的语言理解与推理能力,但在问答中仍面临知识覆盖不足和事实幻觉等问题。知识图谱能够为大语言模型提供结构化、可追溯的事实依据,已成为提升其回答可靠性的重要途径。然而,现有方法通常需要针对特定知识库进行昂贵的模型训练,难以适应未见过的知识库;面对包含数百万实体和海量事实的大规模知识库时,也面临较高的检索成本。为解决上述问题,作者团队提出了大语言模型与知识图谱基础检索器协作框架LLM-KGFR,整体框架如图1所示。
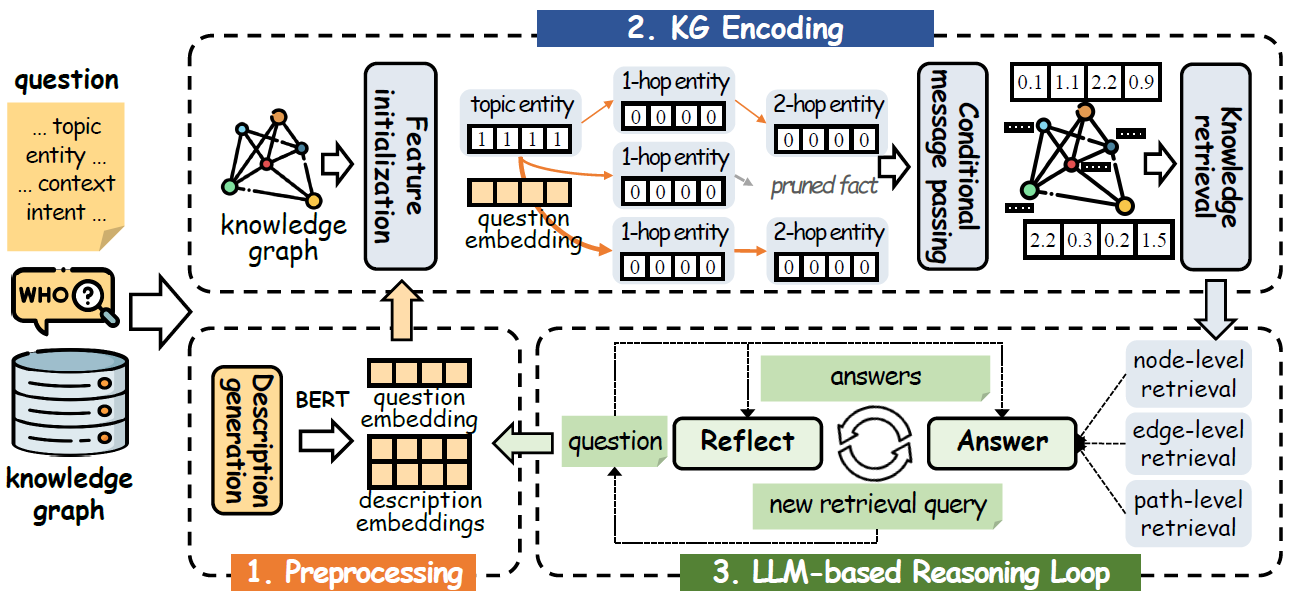
图1-知识图谱通用检索器与大模型协作推理框架
为了解决上述问题,作者提出了大语言模型与知识图谱基础检索器协作框架LLM-KGFR。该框架利用大语言模型生成统一的关系描述,并根据实体在问题中的角色进行初始化,使模型无需重新训练即可处理未见知识图谱;同时,设计非对称渐进传播机制,对高连接关系进行选择性约束,在保留关键推理路径的同时控制检索规模。此外,KGFR通过节点、边和路径三个层次的接口向大语言模型提供候选答案、相关事实和推理路径,形成“检索—推理—反思—再检索”的协作闭环。实验表明,LLM-KGFR在多个类型的大量问答基准上取得了优越性能,并且可以无需微调参数直接应用在未见过的新知识库上,具有较强的泛用性。
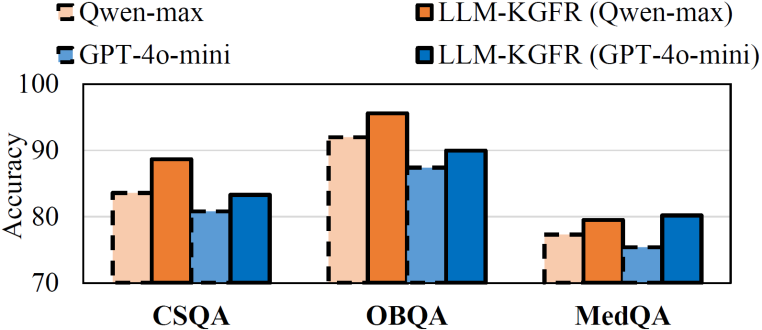
图2-LLM-KGFR在未见问答数据集上的零样本泛化性能
相关论文已被国际权威期刊《IEEE Transactions on Knowledge and Data Engineering》(IEEE TKDE)录用。论文第一作者为伟德源自英国1946崔员宁老师,合作者包括南京大学孙泽群助理教授、胡伟教授和南京信息工程大学网络空间安全学院付章杰教授。IEEE TKDE是数据管理、知识工程与人工智能领域的重要国际期刊,属于中国计算机学会(CCF)推荐的A类期刊。
论文信息:KGFR: A Foundation Retriever for Generalized Knowledge Graph Question Answering, Yuanning Cui, Zequn Sun, Wei Hu, and Zhangjie Fu. IEEE Transactions on Knowledge and Data Engineering. 论文预印版已发布:https://arxiv.org/pdf/2511.04093
(图文:崔员宁)
